研究人员在 MLOps 平台中发现 20 多个供应链漏洞
时间:2024-8-26 21:04 作者:之参博客 分类: 网络相关
网络安全研究人员发现 20 多个可能被用于攻击 MLOps 平台的漏洞,并警告机器学习 (ML) 软件供应链中存在安全风险。
这些漏洞被描述为固有和基于实现的缺陷,可能会造成严重后果,从任意代码执行到加载恶意数据集。
MLOps 平台提供设计和执行 ML 模型管道的功能,其中模型注册表充当用于存储和版本训练的 ML 模型的存储库。然后可以将这些模型嵌入到应用程序中,或允许其他客户端使用 API(又称模型即服务)查询它们。
JFrog 研究人员在一份详细报告中表示: “固有漏洞是由目标技术所使用的底层格式和流程导致的漏洞。”
一些固有漏洞的例子包括滥用 ML 模型来运行攻击者选择的代码,利用模型在加载时支持自动代码执行的事实(例如,Pickle 模型文件)。
这种行为还扩展到某些数据集格式和库,允许自动执行代码,从而在简单加载公开可用的数据集时可能打开恶意软件攻击的大门。
另一个固有漏洞实例涉及 JupyterLab(以前称为 Jupyter Notebook),这是一个基于 Web 的交互式计算环境,使用户能够执行代码块(或单元)并查看相应的结果。
研究人员指出:“许多人不知道的一个固有问题是,在 Jupyter 中运行代码块时如何处理 HTML 输出。Python 代码的输出可能会发出 HTML 和 [JavaScript],而浏览器会很乐意呈现这些内容。”
这里的问题是,JavaScript 结果在运行时不会受到父 Web 应用程序的沙盒保护,并且父 Web 应用程序可以自动运行任意 Python 代码。
换句话说,攻击者可以输出恶意的 JavaScript 代码,以便在当前的 JupyterLab 笔记本中添加新单元,将 Python 代码注入其中,然后执行它。在利用跨站点脚本 (XSS) 漏洞的情况下尤其如此。
为此,JFrog 表示,它发现了 MLFlow 中的一个 XSS 漏洞 ( CVE-2024-27132 ,CVSS 评分:7.5),该漏洞源于运行不受信任的配方时缺乏足够的清理,从而导致 JupyterLab 中的客户端代码执行。
研究人员表示:“这项研究的主要结论之一是,我们需要将 ML 库中的所有 XSS 漏洞视为潜在的任意代码执行,因为数据科学家可能会将这些 ML 库与 Jupyter Notebook 一起使用。”
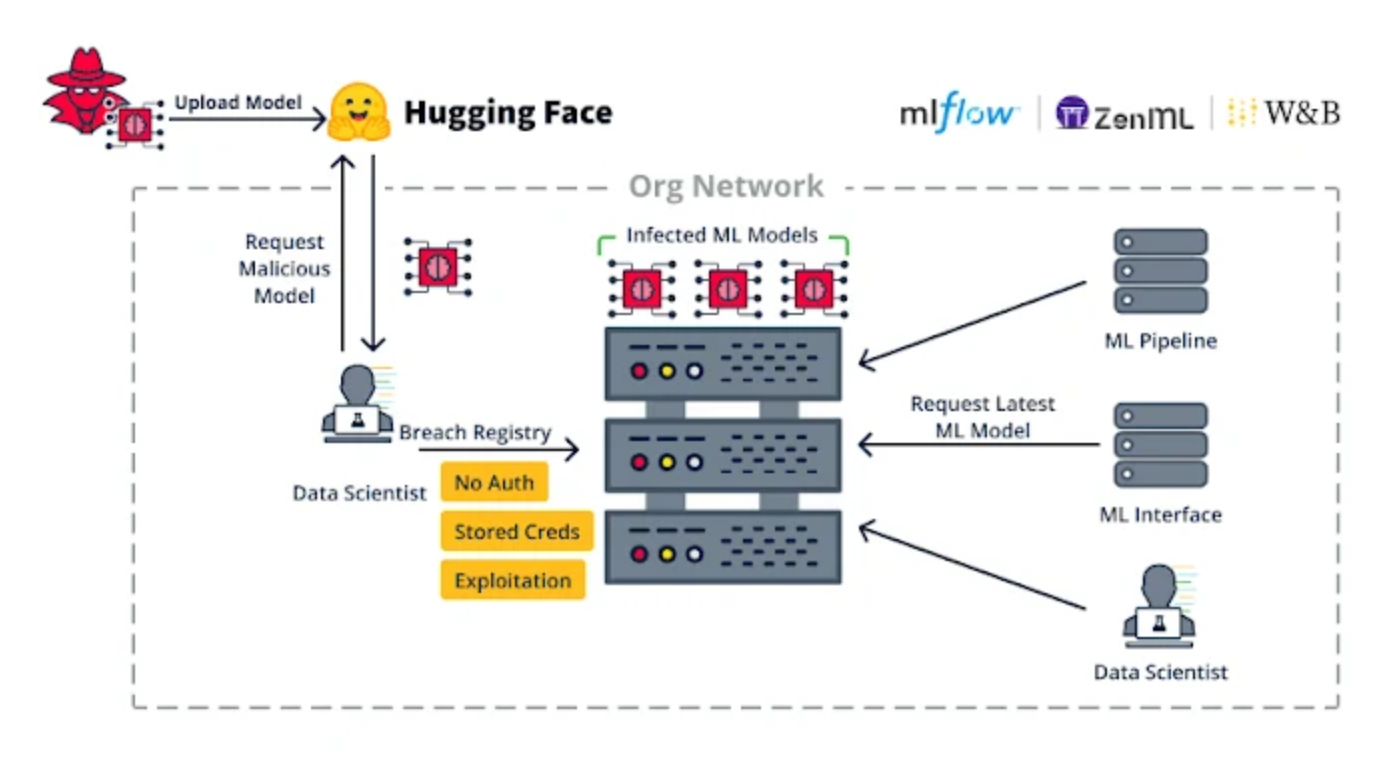
第二组缺陷与实施弱点有关,例如 MLOps 平台缺乏身份验证,这可能允许具有网络访问权限的威胁行为者通过滥用 ML Pipeline 功能来获得代码执行能力。
这些威胁并不是理论上的,出于经济动机的攻击者会滥用此类漏洞来部署加密货币矿工,正如未修补的 Anyscale Ray( CVE-2023-48022 ,CVSS 评分:9.8)的情况一样。
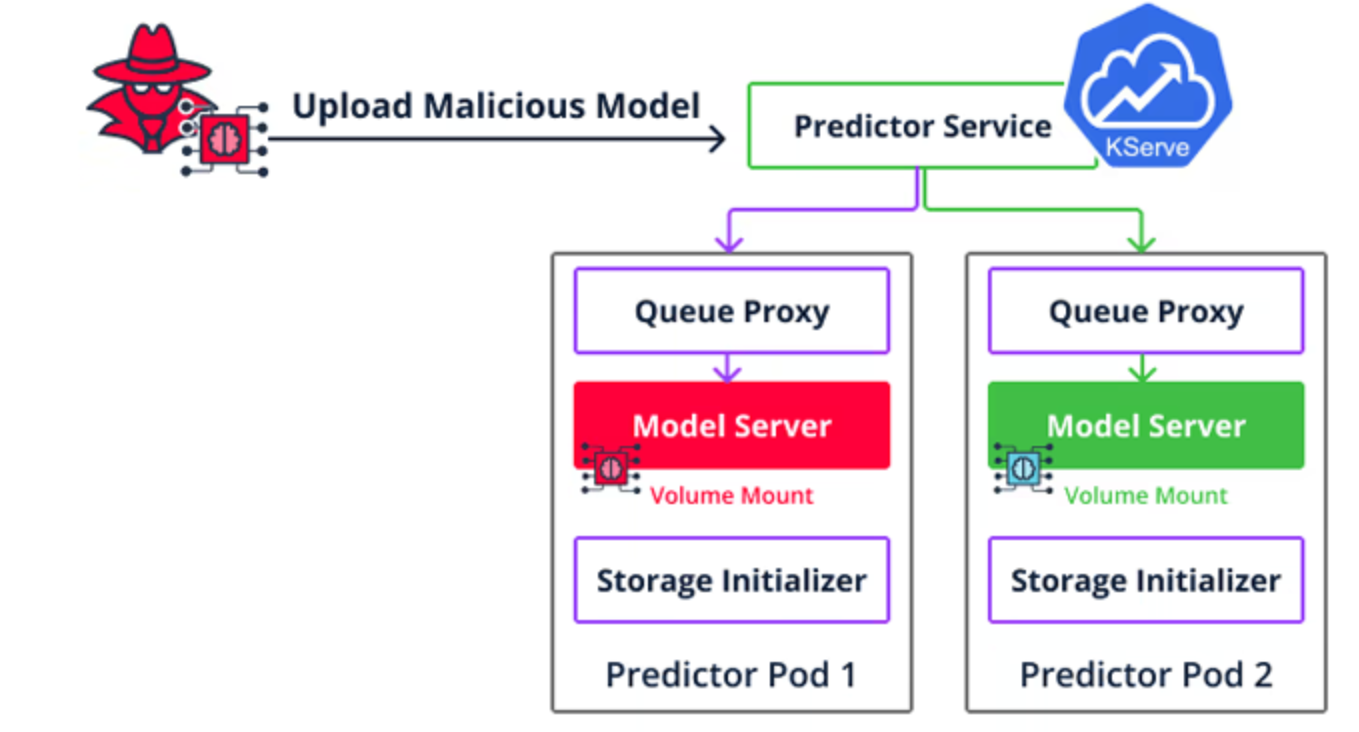
第二种类型的实施漏洞是针对 Seldon Core 的容器逃逸,它使攻击者能够超越代码执行,在云环境中横向移动,并通过将恶意模型上传到推理服务器来访问其他用户的模型和数据集。
这些漏洞串联起来的最终结果是,它们不仅可以被用作武器来渗透和传播到组织内部,而且还能危害服务器。
研究人员表示:“如果你正在部署一个允许模型服务的平台,那么你现在应该知道,任何可以提供新模型的人实际上也可以在该服务器上运行任意代码。”“确保运行模型的环境完全隔离,并针对容器逃逸进行强化。”
此次披露之际,Palo Alto Networks Unit 42详细介绍了开源 LangChain 生成 AI 框架中两个现已修补的漏洞 (CVE-2023-46229 和 CVE-2023-44467),这两个漏洞可能分别允许攻击者执行任意代码和访问敏感数据。
上个月,Trail of Bits 还披露了检索增强生成 (RAG) 开源聊天机器人应用程序 Ask Astro 中的四个问题,这些问题可能导致聊天机器人输出中毒、文档提取不准确以及潜在的拒绝服务 (DoS)。
正如人工智能应用程序中暴露出的安全问题一样,人们也设计出一些技术来毒害训练数据集,最终目的是诱骗大型语言模型 (LLM) 生成易受攻击的代码。
康涅狄格大学的一组学者表示:“与最近将恶意负载嵌入代码可检测或不相关部分(例如注释)的攻击不同,CodeBreaker 利用 LLM(例如 GPT-4)进行复杂的负载转换(不影响功能),确保用于微调的毒化数据和生成的代码都可以逃避强大的漏洞检测。 ”